JIRA¶
The Jira service synchronizes
data between Jira from Atlassian and the
life cycle management extension Sphinx-Needs from
useblocks.
The implementation is based on the services mechanism of Sphinx-Needs.
The Jira service allows to retrieve external data during documentation build and
to create Sphinx-Needs objects based on this data.
After the created Sphinx-Needs objects support every function from
Sphinx-Needs, which includes Filtering, Linking,
Updating and much more.
Options¶
The following options can be used inside .. needservice:: Jira and related directives.
query¶
A query string, which must be valid to JQL.
prefix¶
A string, which is taken as prefix for the need-id. E.g. CB_IMPORT_ –> CB_IMPORT_005.
Config¶
Most configuration needs to be done via the service configuration in your conf.py file.
Hint
For details about most configuration options, please take a look into the common configuration description.
The following documentation describes service specific information for Jira only.
endpoint¶
Default: /rest/api/2/search
See also endpoint for more details.
query¶
String, which must follow the JQL. notation.
See also query for more details.
id_prefix¶
A prefix for the final ID of the created need. Can get important, if the IDs from Jira are not unique.
Example: JIRA_ will create IDs like JIRA_TEST-3.
convert_content¶
If True, the format used by JIRA for descriptions gets transformed to rst. This allows Sphinx to render the content.
Otherwise the default format is kept and printed, which would contain also the style
specific information like h3. for titles.
Drawback: The used converter libraries are quite slow and it will take 1-3 seconds per issue.
Default: True
Example¶
Inside your conf.py file:
jira_content = """
{{data.fields.description}}"""
needs_services = {
"jira_config": {
"url": "http://127.0.0.1:8081",
"user": "test",
"password": "test",
"id_prefix": "JIRA_",
"query": "project = PX",
"content": jira_content,
"mappings": {
"id": ["key"],
"type": "spec",
"title": ["fields", "summary"],
"status": ["fields", "status", "name"],
},
"extra_data": {
"Original Type": ["fields", "issuetype", "name"],
"Original Assignee": ["fields", "assignee", "displayName"],
},
}
}
Inside any rst file of your Sphinx project:
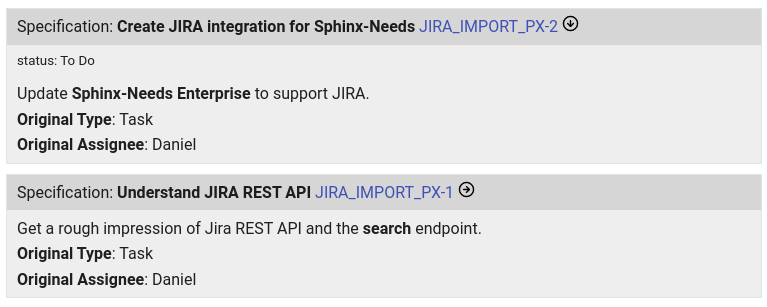
.. needservice:: jira_config
:query: project = PX
:prefix: JIRA_IMPORT
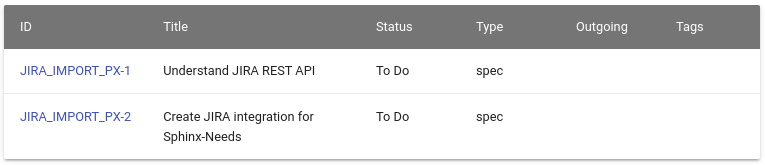
.. needtable::
:filter: "JIRA_IMPORT" in id
Result
Hint
The below examples are just images, as no Jira instance was available during documentation build.